

Descenso de Gradiente: La Ruta Inteligente hacia la Optimización en Cálculo Multivariante
30 JUL., 2026
//1 min. de Lectura
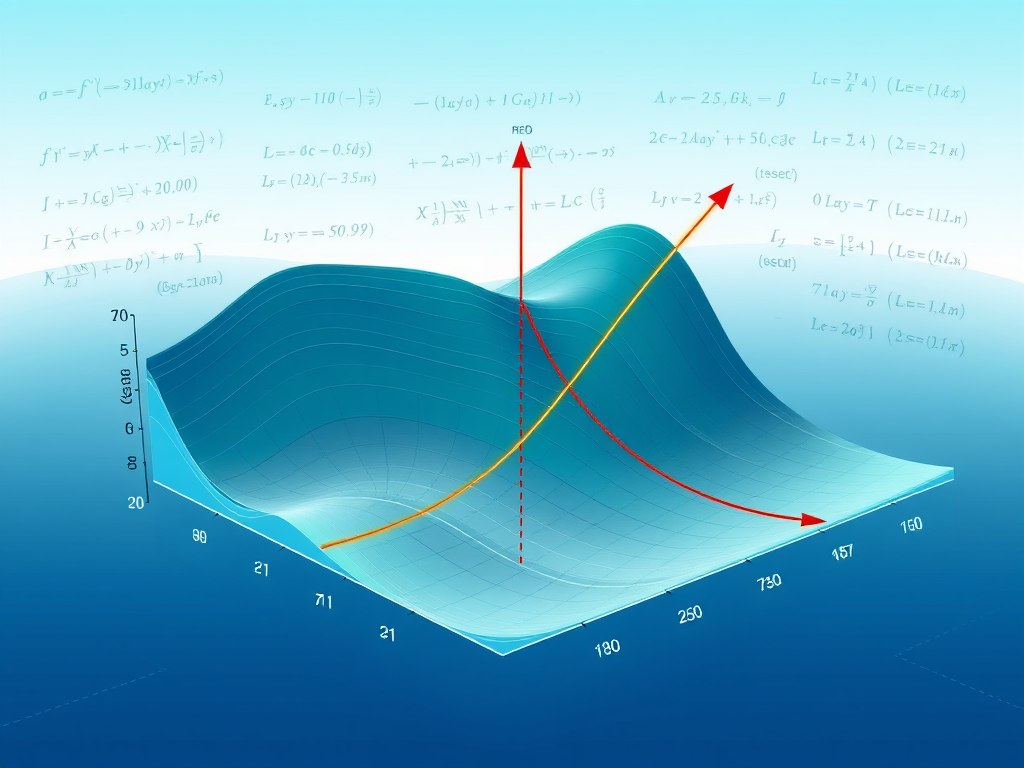
El descenso de gradiente es un algoritmo de optimización fundamental utilizado en el aprendizaje automático y en la estadística para minimizar funciones. En el contexto del cálculo multivariante, el descenso de gradiente se extiende para trabajar con funciones que tienen múltiples variables. Este artículo explora el concepto de descenso de gradiente, su aplicación en el cálculo multivariante, y su importancia en la optimización de modelos.
¿Qué es el Descenso de Gradiente?
El descenso de gradiente es un método iterativo que busca encontrar los valores de los parámetros que minimizan una función de costo o pérdida. La idea básica es utilizar el gradiente (o derivada) de la función para determinar la dirección en la que se debe mover para reducir el valor de la función.
Conceptos Clave
- Función de Costo: Es la función que queremos minimizar. En el contexto del aprendizaje automático, puede ser la función que mide el error entre las predicciones de un modelo y los valores reales.
- Gradiente: Es un vector que contiene las derivadas parciales de la función con respecto a cada una de las variables. Indica la dirección de mayor incremento de la función.
- Tasa de Aprendizaje (α): Es un parámetro que determina el tamaño de los pasos que se dan en la dirección del gradiente.
Descenso de Gradiente en Cálculo Multivariante
En el cálculo multivariante, las funciones pueden depender de múltiples variables. El descenso de gradiente se adapta a este contexto considerando el gradiente como un vector que apunta en la dirección de mayor incremento.
Fórmula del Descenso de Gradiente
Para una función \(f(x_1,x_2,\ldots,x_n) \), el descenso de gradiente se actualiza de la siguiente manera: $$ \theta^{(t+1)} = \theta^{(t)} - \alpha \nabla f(\theta^{(t)}) $$
donde:
- \(\theta^{(t)}\) es el vector de parámetros en la iteración \(t\).
- \(\alpha\) es la tasa de aprendizaje.
- \(\nabla f(\theta^{(t)}\) es el gradiente de la función en el punto \(\theta^{(t)}\)
Proceso Iterativo
- Inicialización: Comienza con valores iniciales para los parámetros.
- Cálculo del Gradiente: Calcula el gradiente de la función de costo en el punto actual.
- Actualización de Parámetros: Ajusta los parámetros en la dirección opuesta al gradiente, multiplicada por la tasa de aprendizaje.
- Repetir: Repite los pasos 2 y 3 hasta que la función de costo converja a un mínimo o hasta que se alcance un número máximo de iteraciones.
Convergencia y Desafíos
El descenso de gradiente puede enfrentar varios desafíos:
- Elección de la Tasa de Aprendizaje: Si es demasiado alta, el algoritmo puede divergir; si es demasiado baja, la convergencia puede ser muy lenta.
- Mínimos Locales: En funciones no convexas, el algoritmo puede converger a un mínimo local en lugar del mínimo global.
- Escalabilidad: En funciones con muchas variables, el cálculo del gradiente puede ser computacionalmente costoso.
Comentarios
0Sin comentarios
Sé el primero en compartir tu opinión.
También te puede interesar
Descubre más contenido relacionado que podría ser de tu interés

Visualiza Sesgos: SHAP Values Detectan Discriminación en tus Modelos
exploraremos cómo esta técnica matemática no solo explica predicciones, sino que desenmascara sesgos ocultos en algoritmos aparentemente objetivos
