


Introducción a Machine Learning con Scikit-Learn: Guía Completa para Principiantes
Aprende machine learning con Scikit-Learn. Guía paso a paso para principiantes con ejemplos prácticos en Python.
¡Da tus primeros pasos en machine learning con Scikit-Learn! En este tutorial completo te guiaré paso a paso para que aprendas los fundamentos del aprendizaje automático usando la biblioteca más popular de Python.
Objetivo: Aprender los conceptos básicos de machine learning y cómo implementar modelos simples de clasificación y regresión usando Scikit-Learn.
Paso 1: ¿Qué es Machine Learning?
El machine learning (aprendizaje automático) es la capacidad de las computadoras para aprender patrones desde los datos sin ser programadas explícitamente.
Los 3 tipos principales:
- Aprendizaje supervisado: Predecir valores usando datos etiquetados
- Aprendizaje no supervisado: Encontrar patrones en datos no etiquetados
- Aprendizaje por refuerzo: Aprender mediante interacción y recompensas
Paso 2: Configuración Inicial
Instala las bibliotecas necesarias. Abre tu terminal o prompt de comandos y escribe:
pip install pandas numpy matplotlib seaborn scikit-learnUna vez instalado, puedes importarlo en tu código Python:
# Importar bibliotecas esenciales
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Importar componentes de scikit-learn
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, mean_squared_error, confusion_matrix
# Configurar estilo de visualización
sns.set_style("whitegrid")
plt.rcParams['figure.figsize'] = (10, 6)
np.random.seed(42) # Para reproducibilidadPaso 3: Primer Conjunto de Datos: Iris
Vamos a trabajar con el famoso dataset Iris, perfecto para empezar.
from sklearn.datasets import load_iris
# Cargar el dataset
iris = load_iris()
X = iris.data # Características (features)
y = iris.target # Variable objetivo (target)
# Convertir a DataFrame para mayor comodidad
iris_df = pd.DataFrame(X, columns=iris.feature_names)
iris_df['species'] = y
print("Primeras filas del dataset Iris:")
print(iris_df.head())
print(f"\nForma de los datos: {X.shape}")
print(f"Nombres de las características: {iris.feature_names}")
print(f"Nombres de las clases: {iris.target_names}")Paso 4: Entendiendo el Problema: Clasificación
El dataset Iris es un problema de clasificación: queremos predecir la especie de flor basándonos en sus medidas.
# Explorar las clases
print("Distribución de clases:")
print(iris_df['species'].value_counts())
# Visualizar la relación entre características
sns.pairplot(iris_df, hue='species', palette='viridis')
plt.suptitle('Pairplot del Dataset Iris', y=1.02)
plt.show()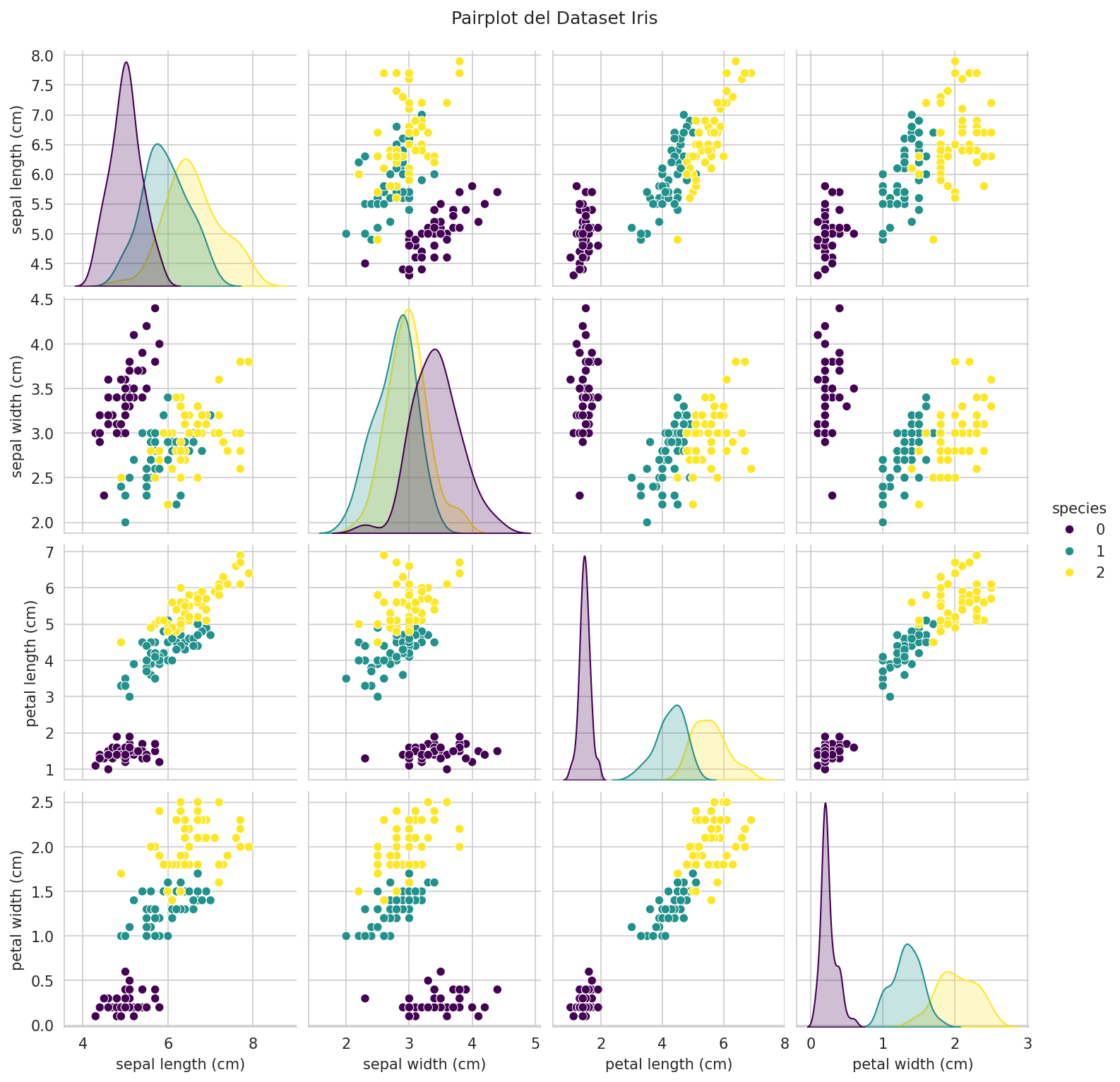
Paso 5: Flujo de Trabajo Básico de ML
El proceso estándar tiene estos pasos:
- Preparar y dividir los datos
- Elegir y entrenar un modelo
- Evaluar el modelo
- Hacer predicciones
Paso 6: Preparar y Dividir los Datos
# Dividir en conjunto de entrenamiento y prueba
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"Conjunto de entrenamiento: {X_train.shape[0]} muestras")
print(f"Conjunto de prueba: {X_test.shape[0]} muestras")
# Escalar características (importante para muchos algoritmos)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)Paso 7: Elegir y Entrenar un Modelo
Primer Modelo: Regresión Logística
# Crear y entrenar el modelo
modelo_lr = LogisticRegression(random_state=42)
modelo_lr.fit(X_train_scaled, y_train)
# Hacer predicciones
y_pred_lr = modelo_lr.predict(X_test_scaled)
print("Predicciones de Regresión Logística:")
print(y_pred_lr[:10])
print("Valores reales:")
print(y_test[:10])Segundo Modelo: Árbol de Decisión
# Crear y entrenar el modelo
modelo_tree = DecisionTreeClassifier(max_depth=3, random_state=42)
modelo_tree.fit(X_train, y_train) # Nota: no necesita escalado
# Hacer predicciones
y_pred_tree = modelo_tree.predict(X_test)
print("Predicciones de Árbol de Decisión:")
print(y_pred_tree[:10])Paso 8: Evaluar los Modelos
# Evaluar Regresión Logística
accuracy_lr = accuracy_score(y_test, y_pred_lr)
print(f"Precisión de Regresión Logística: {accuracy_lr:.3f}")
# Evaluar Árbol de Decisión
accuracy_tree = accuracy_score(y_test, y_pred_tree)
print(f"Precisión de Árbol de Decisión: {accuracy_tree:.3f}")
# Matriz de confusión para el mejor modelo
cm = confusion_matrix(y_test, y_pred_lr)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=iris.target_names,
yticklabels=iris.target_names)
plt.title('Matriz de Confusión - Regresión Logística')
plt.ylabel('Verdadero')
plt.xlabel('Predicción')
plt.show()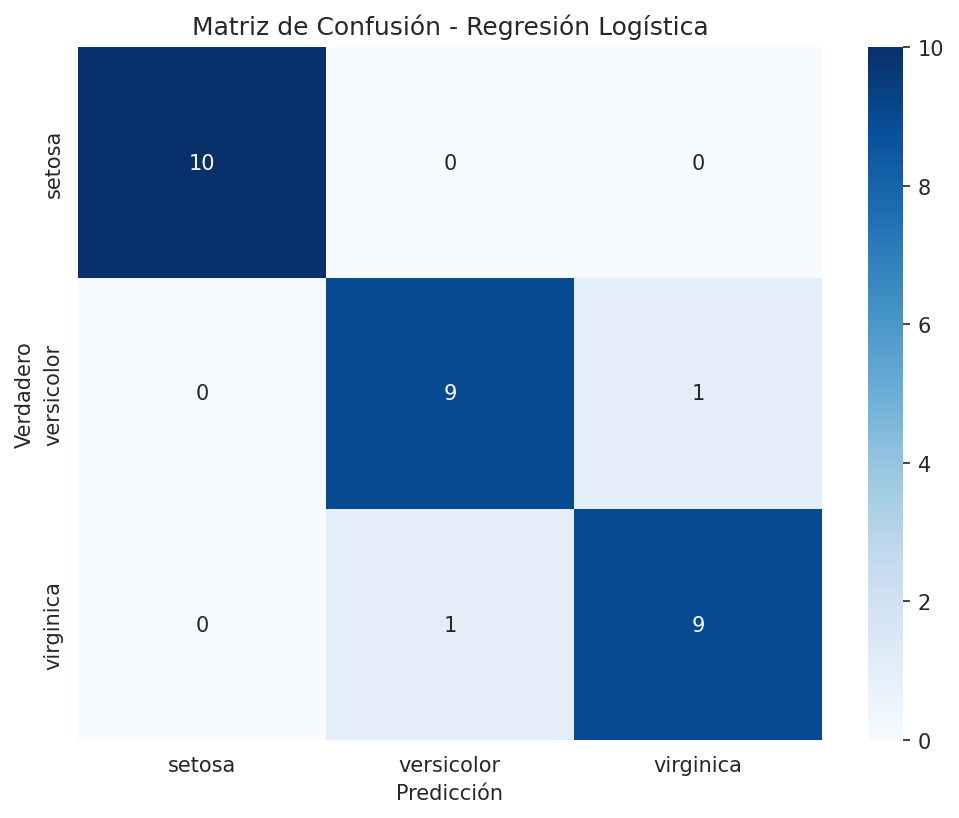
Paso 9: Regresión: Predecir Valores Continuos
# Crear un problema de regresión (predecir longitud del pétalo)
from sklearn.ensemble import RandomForestRegressor
# Preparar datos para regresión
X_reg = iris.data[:, :3] # Usar solo 3 características
y_reg = iris.data[:, 3] # Longitud del pétalo como variable objetivo
# Dividir datos
X_train_reg, X_test_reg, y_train_reg, y_test_reg = train_test_split(
X_reg, y_reg, test_size=0.2, random_state=42
)
# Entrenar modelo de regresión
modelo_rf = RandomForestRegressor(n_estimators=100, random_state=42)
modelo_rf.fit(X_train_reg, y_train_reg)
# Predecir y evaluar
y_pred_reg = modelo_rf.predict(X_test_reg)
mse = mean_squared_error(y_test_reg, y_pred_reg)
print(f"Error Cuadrático Medio (MSE): {mse:.4f}")
# Visualizar predicciones vs valores reales
plt.figure(figsize=(10, 6))
plt.scatter(y_test_reg, y_pred_reg, alpha=0.7)
plt.plot([y_test_reg.min(), y_test_reg.max()],
[y_test_reg.min(), y_test_reg.max()], 'r--', lw=2)
plt.xlabel('Valor Real')
plt.ylabel('Predicción')
plt.title('Predicciones vs Valores Reales - Random Forest')
plt.show()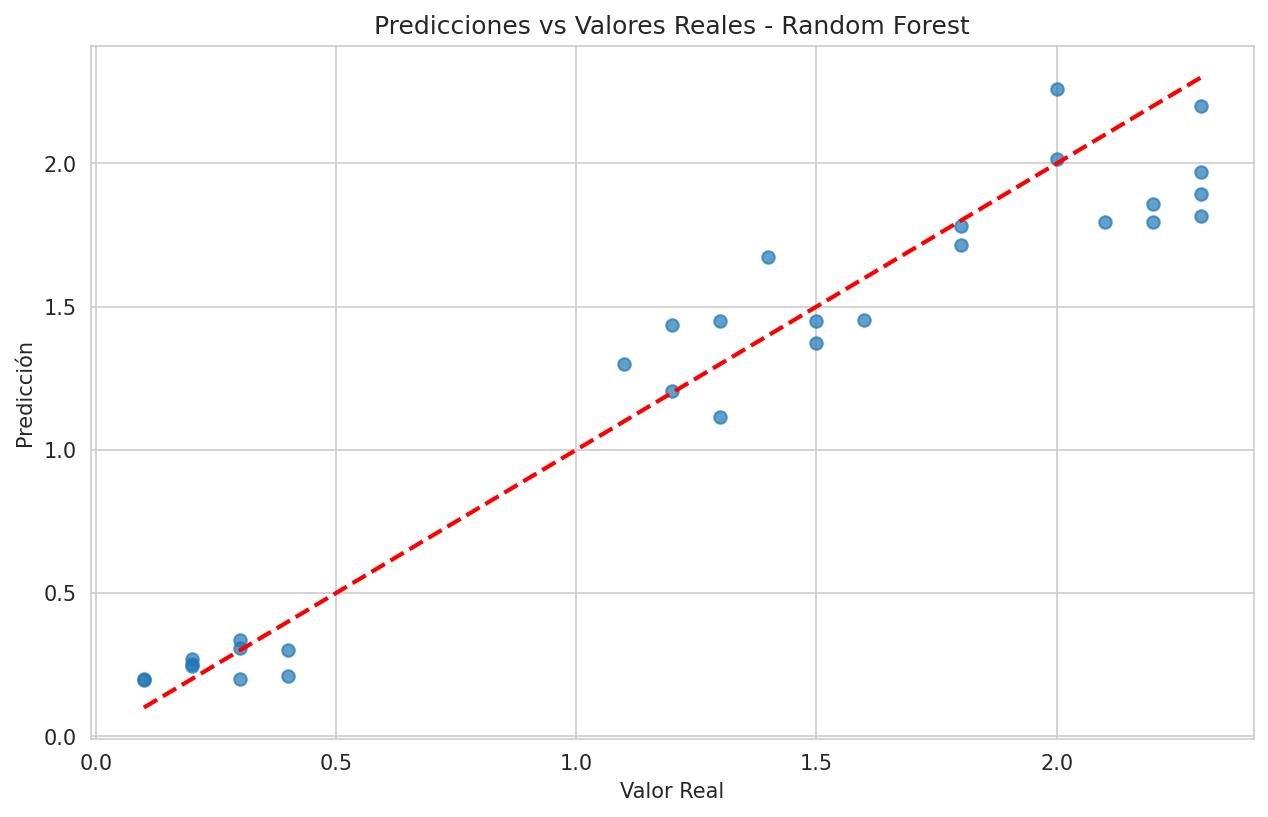
Paso 10: Validación Cruzada
from sklearn.model_selection import cross_val_score
# Validación cruzada para Regresión Logística
scores_lr = cross_val_score(LogisticRegression(), X_train_scaled, y_train, cv=5)
print(f"Precisión Regresión Logística (CV): {scores_lr.mean():.3f} (±{scores_lr.std():.3f})")
# Validación cruzada para Árbol de Decisión
scores_tree = cross_val_score(DecisionTreeClassifier(), X_train, y_train, cv=5)
print(f"Precisión Árbol de Decisión (CV): {scores_tree.mean():.3f} (±{scores_tree.std():.3f})")Paso 11: Ajuste de Hiperparámetros
from sklearn.model_selection import GridSearchCV
# Definir parámetros a probar
param_grid = {
'max_depth': [2, 3, 4, 5, None],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# Búsqueda de mejores parámetros
grid_search = GridSearchCV(
DecisionTreeClassifier(random_state=42),
param_grid,
cv=5,
scoring='accuracy'
)
grid_search.fit(X_train, y_train)
print(f"Mejores parámetros: {grid_search.best_params_}")
print(f"Mejor precisión: {grid_search.best_score_:.3f}")
# Usar el mejor modelo
mejor_modelo = grid_search.best_estimator_
y_pred_mejor = mejor_modelo.predict(X_test)
print(f"Precisión en prueba con mejor modelo: {accuracy_score(y_test, y_pred_mejor):.3f}")Paso 12: Guardar y Cargar Modelos
import joblib
# Guardar el modelo entrenado
joblib.dump(mejor_modelo, 'mejor_modelo_iris.pkl')
# Más tarde... cargar el modelo
modelo_cargado = joblib.load('mejor_modelo_iris.pkl')
# Usar el modelo cargado
nueva_flor = np.array([[5.1, 3.5, 1.4, 0.2]]) # Ejemplo de nueva flor
prediccion = modelo_cargado.predict(nueva_flor)
print(f"Predicción para nueva flor: {iris.target_names[prediccion[0]]}")Paso 13: Flujo de Trabajo Completo Resumido
# 1. Cargar y explorar datos
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
# 2. Dividir datos
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 3. Preprocesar (si es necesario)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 4. Elegir y entrenar modelo
modelo = LogisticRegression(random_state=42)
modelo.fit(X_train, y_train)
# 5. Evaluar modelo
y_pred = modelo.predict(X_test)
print(f"Precisión: {accuracy_score(y_test, y_pred):.3f}")
# 6. Usar para predicciones
nueva_prediccion = modelo.predict(scaler.transform([[5.1, 3.5, 1.4, 0.2]]))
print(f"Especie predicha: {iris.target_names[nueva_prediccion[0]]}")Paso 14: Próximos Pasos
-
Explorar más algoritmos:
- SVM, KNeighborsClassifier, RandomForestClassifier
- KMeans (clustering no supervisado)
-
Procesamiento de texto:
- Usar CountVectorizer o TfidfVectorizer
-
Redes neuronales:
- Avanzar a TensorFlow o PyTorch
-
Proyectos prácticos:
- Competencias de Kaggle
- Proyectos personales con tus propios datos
Conclusión
¡Felicidades! Ahora dominas los fundamentos de machine learning con Scikit-Learn. Practica con tus propios datasets y explora más algoritmos avanzados. Si tienes preguntas, déjalas en los comentarios.
Para más tutoriales sobre ciencia de datos y Python, visita nuestra sección de tutoriales.
¡Con estos conocimientos ya puedes crear tus primeros modelos de machine learning en Python!
💡 Tip Importante
🤖 Mejores Prácticas para Machine Learning
Para desarrollar modelos efectivos de machine learning, considera estos consejos:
Empieza simple: No uses modelos complejos sin necesidad.
Comprende los datos: Visualiza y explora antes de modelar.
Divide tus datos: Nunca evalúes en los mismos datos de entrenamiento.
Usa validación cruzada: Para una evaluación más robusta.
Ajusta hiperparámetros: Mejora el rendimiento con GridSearchCV.
Guarda tus modelos: Usa joblib para persistir modelos entrenados.
Itera: Machine learning es un proceso de prueba y error.
Practica: Cuanto más practiques, mejor entenderás los conceptos.
📚 Documentación: Revisa la documentación completa de scikit-learn aquí
¡Estos consejos te ayudarán a construir modelos de machine learning efectivos!


No hay comentarios aún
Sé el primero en comentar este tutorial.