

Procesamiento de Lenguaje Natural (NLP) con Python: Guía Completa para Principiantes
Aprende procesamiento de lenguaje natural con Python. Guía paso a paso para principiantes con ejemplos prácticos en Python.
¡Da tus primeros pasos en el procesamiento de lenguaje natural con Python! En este tutorial completo te guiaré paso a paso para que aprendas las técnicas esenciales para trabajar con texto, desde preprocesamiento hasta análisis avanzado.
Objetivo: Aprender los fundamentos del procesamiento de lenguaje natural usando Python, incluyendo preprocesamiento de texto, análisis exploratorio y técnicas de modelado.
Paso 1: ¿Qué es el Procesamiento de Lenguaje Natural?
El NLP es la capacidad de las computadoras para entender, interpretar y generar lenguaje humano. Aplicaciones incluyen chatbots, análisis de sentimientos, traducción automática y resumen de textos.
# Importar librerías esenciales
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud
# Librerías específicas de NLP
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import SnowballStemmer, WordNetLemmatizer
import spacy
import re
# Descargar recursos de NLTK (ejecutar solo la primera vez)
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('vader_lexicon')
# Configuración
sns.set_style("whitegrid")
plt.rcParams['figure.figsize'] = (12, 6)
np.random.seed(42)Paso 2: Primeros Pasos: Texto de Ejemplo
# Texto de ejemplo para trabajar
texto_ejemplo = """
El aprendizaje automático es una rama de la inteligencia artificial que se centra en desarrollar
sistemas que pueden aprender de los datos. El procesamiento de lenguaje natural permite a las
máquinas entender e interpretar el lenguaje humano. Los modelos de deep learning han revolucionado
el campo del NLP en los últimos años, achieving resultados impresionantes en traducción,
resumen de texto y análisis de sentimientos.
"""
print("Texto original:")
print(texto_ejemplo)Paso 3: Preprocesamiento de Texto
Tokenización
# Tokenización (dividir en palabras)
tokens = word_tokenize(texto_ejemplo.lower()) # Convertir a minúsculas
print(f"Tokens: {tokens[:10]}...") # Primeros 10 tokens
# Tokenización de oraciones
from nltk.tokenize import sent_tokenize
oraciones = sent_tokenize(texto_ejemplo)
print(f"\nOraciones: {oraciones}")Limpieza de Texto
def limpiar_texto(texto):
# Convertir a minúsculas
texto = texto.lower()
# Eliminar caracteres especiales y números
texto = re.sub(r'[^a-záéíóúñ\s]', '', texto)
# Eliminar espacios extras
texto = re.sub(r'\s+', ' ', texto).strip()
return texto
texto_limpio = limpiar_texto(texto_ejemplo)
print("Texto limpio:")
print(texto_limpio)Eliminación de Stopwords
# Stopwords en español
stop_words_es = set(stopwords.words('spanish'))
print(f"Stopwords en español: {list(stop_words_es)[:10]}...")
# Filtrar stopwords
tokens_limpios = [token for token in tokens if token not in stop_words_es and len(token) > 2]
print(f"\nTokens después de eliminar stopwords: {tokens_limpios[:10]}...")Stemming y Lematización
# Stemming (reducción a raíz)
stemmer = SnowballStemmer('spanish')
stems = [stemmer.stem(token) for token in tokens_limpios]
print(f"Stems: {stems[:10]}...")
# Lematización (forma base lingüísticamente correcta)
lemmatizer = WordNetLemmatizer()
lemmas = [lemmatizer.lemmatize(token) for token in tokens_limpios]
print(f"Lemmas: {lemmas[:10]}...")Paso 4: Análisis Exploratorio de Texto
Frecuencia de Palabras
from collections import Counter
# Contar frecuencia de palabras
frecuencia = Counter(tokens_limpios)
palabras_comunes = frecuencia.most_common(10)
print("Palabras más comunes:")
for palabra, count in palabras_comunes:
print(f"{palabra}: {count}")
# Visualización
plt.figure(figsize=(10, 6))
palabras, counts = zip(*palabras_comunes)
plt.bar(palabras, counts)
plt.title('Palabras más frecuentes')
plt.xticks(rotation=45)
plt.show()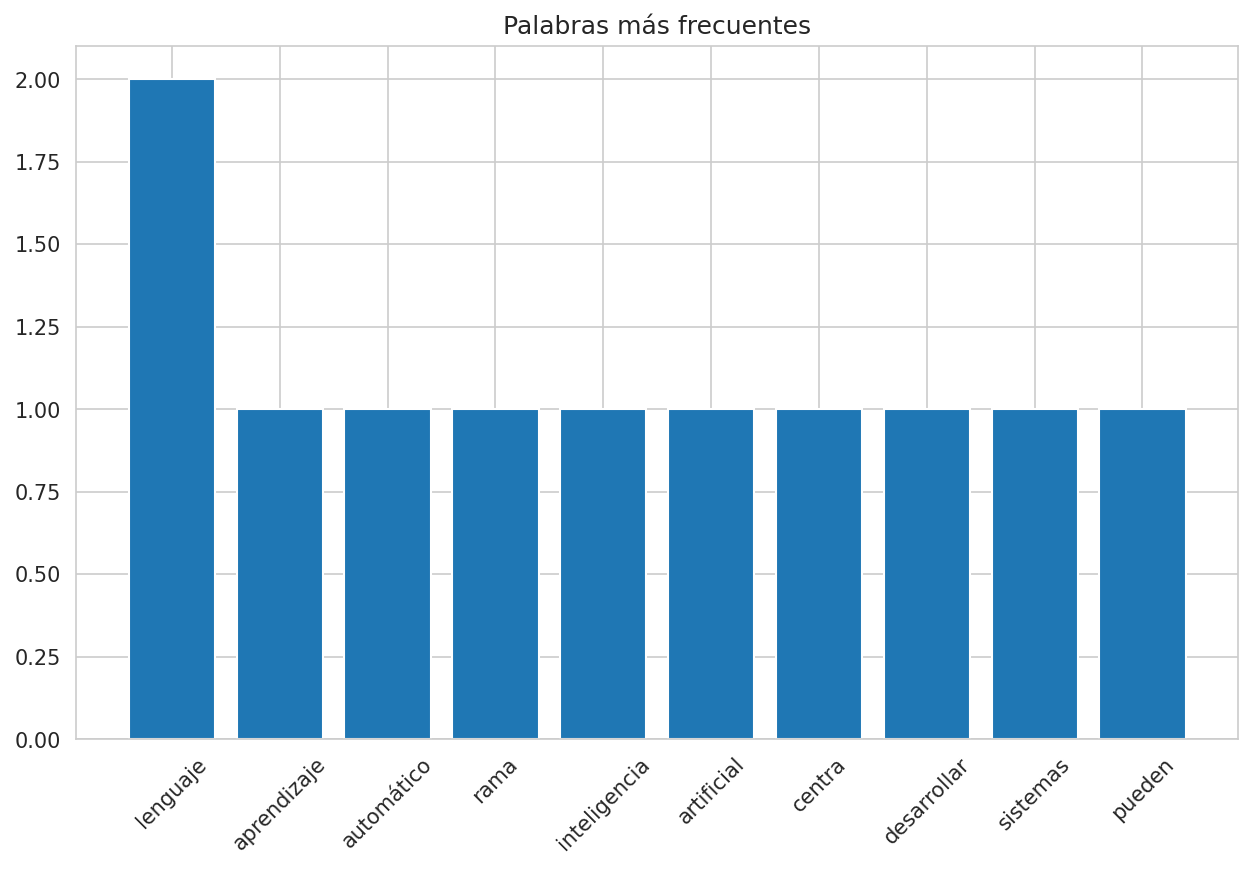
Nube de Palabras
# Crear nube de palabras
wordcloud = WordCloud(
width=800,
height=400,
background_color='white',
colormap='viridis'
).generate(' '.join(tokens_limpios))
plt.figure(figsize=(12, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('Nube de Palabras del Texto')
plt.show()
Paso 5: Representación Vectorial de Texto
Bag of Words (BoW)
from sklearn.feature_extraction.text import CountVectorizer
# Ejemplo con múltiples documentos
documentos = [
"el gato corre en el jardín",
"el perro juega en el parque",
"el gato y el perro son amigos"
]
# Crear matriz BoW
vectorizer = CountVectorizer()
X_bow = vectorizer.fit_transform(documentos)
# Convertir a DataFrame para mejor visualización
df_bow = pd.DataFrame(
X_bow.toarray(),
columns=vectorizer.get_feature_names_out()
)
print("Matriz Bag of Words:")
print(df_bow)TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer
# Crear matriz TF-IDF
tfidf_vectorizer = TfidfVectorizer()
X_tfidf = tfidf_vectorizer.fit_transform(documentos)
# Convertir a DataFrame
df_tfidf = pd.DataFrame(
X_tfidf.toarray(),
columns=tfidf_vectorizer.get_feature_names_out()
)
print("\nMatriz TF-IDF:")
print(df_tfidf.round(3))Paso 6: Análisis de Sentimientos
from nltk.sentiment import SentimentIntensityAnalyzer
# Analizador de sentimientos
sia = SentimentIntensityAnalyzer()
# Textos para análisis
textos_analisis = [
"Me encanta este producto, es absolutamente increíble!",
"Esto es terrible, no me gusta nada.",
"Es aceptable, pero podría ser mejor."
]
# Analizar sentimientos
print("Análisis de Sentimientos:")
for texto in textos_analisis:
scores = sia.polarity_scores(texto)
print(f"\nTexto: {texto}")
print(f"Puntuación: {scores}")
sentimiento = "Positivo" if scores['compound'] > 0.05 else "Negativo" if scores['compound'] < -0.05 else "Neutral"
print(f"Sentimiento: {sentimiento}")Paso 7: Modelado de Temas con LDA
from sklearn.decomposition import LatentDirichletAllocation
from sklearn.feature_extraction.text import CountVectorizer
# Textos de ejemplo
textos_temas = [
"machine learning inteligencia artificial datos",
"red neuronal deep learning algoritmo",
"procesamiento lenguaje natural texto linguística",
"visión computacional imagen reconocimiento objeto",
"robot automatización inteligencia artificial"
]
# Crear matriz de términos
vectorizer_temas = CountVectorizer(max_features=10)
X_temas = vectorizer_temas.fit_transform(textos_temas)
# Aplicar LDA
lda = LatentDirichletAllocation(n_components=2, random_state=42)
lda.fit(X_temas)
# Mostrar temas
print("Temas identificados:")
for idx, tema in enumerate(lda.components_):
print(f"\nTema {idx + 1}:")
palabras_tema = [vectorizer_temas.get_feature_names_out()[i] for i in tema.argsort()[-5:]]
print(f"Palabras: {', '.join(palabras_tema)}")Paso 8: Word Embeddings con Word2Vec
from gensim.models import Word2Vec
# Entrenar modelo Word2Vec (usando nuestros tokens)
oraciones_entrenamiento = [tokens_limpios] # En la práctica, usarías más datos
modelo_word2vec = Word2Vec(
sentences=oraciones_entrenamiento,
vector_size=100, # Dimensionalidad de los embeddings
window=5, # Contexto alrededor de cada palabra
min_count=1, # Frecuencia mínima de palabra
workers=4, # Número de cores
epochs=10 # Iteraciones de entrenamiento
)
# Obtener embedding de una palabra
try:
embedding = modelo_word2vec.wv['aprendizaje']
print(f"Embedding para 'aprendizaje' (primeros 10 valores): {embedding[:10]}")
# Palabras similares
similares = modelo_word2vec.wv.most_similar('aprendizaje', topn=3)
print(f"\nPalabras similares a 'aprendizaje': {similares}")
except KeyError:
print("Palabra no encontrada en el vocabulario (vocabulario muy pequeño)")Paso 9: Clasificación de Texto con Machine Learning
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
# Datos de ejemplo (en la práctica, usarías un dataset real)
X_textos = [
"excelente producto me encanta",
"terrible no me gusta nada",
"buena calidad precio razonable",
"pésima experiencia cliente",
"maravilloso recomiendo totalmente",
"horrible waste of money"
]
y_etiquetas = [1, 0, 1, 0, 1, 0] # 1: positivo, 0: negativo
# Convertir texto a características
vectorizer_clf = TfidfVectorizer()
X_features = vectorizer_clf.fit_transform(X_textos)
# Dividir datos
X_train, X_test, y_train, y_test = train_test_split(
X_features, y_etiquetas, test_size=0.3, random_state=42
)
# Entrenar modelo
modelo_clf = RandomForestClassifier(random_state=42)
modelo_clf.fit(X_train, y_train)
# Predecir y evaluar
y_pred = modelo_clf.predict(X_test)
print(f"Precisión: {accuracy_score(y_test, y_pred):.2f}")
print("\nReporte de Clasificación:")
print(classification_report(y_test, y_pred))Paso 10: NLP con Transformers (BERT)
# Importar transformers (instalar: pip install transformers)
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
# Análisis de sentimientos con modelo pre-entrenado
classifier = pipeline('sentiment-analysis', model='nlptown/bert-base-multilingual-uncased-sentiment')
textos_bert = [
"Me encanta este producto!",
"No estoy seguro sobre esto",
"Esto es terrible y no funciona"
]
print("Análisis con BERT:")
for texto in textos_bert:
resultado = classifier(texto)
print(f"\nTexto: {texto}")
print(f"Resultado: {resultado[0]}")Paso 11: Proyecto Completo: Análisis de Reseñas
# Ejemplo de flujo completo para análisis de reseñas
def analizar_resenas(resenas):
"""
Función completa para análisis de reseñas
"""
resultados = []
for resena in resenas:
# Limpieza
resena_limpia = limpiar_texto(resena)
# Tokenización
tokens = word_tokenize(resena_limpia)
# Eliminar stopwords
tokens_limpios = [token for token in tokens if token not in stop_words_es and len(token) > 2]
# Análisis de sentimientos
scores = sia.polarity_scores(resena)
sentimiento = "Positivo" if scores['compound'] > 0.05 else "Negativo" if scores['compound'] < -0.05 else "Neutral"
# Guardar resultados
resultados.append({
'resena_original': resena,
'resena_limpia': resena_limpia,
'num_palabras': len(tokens_limpios),
'sentimiento': sentimiento,
'puntuacion': scores['compound']
})
return pd.DataFrame(resultados)
# Probar con reseñas de ejemplo
resenas_ejemplo = [
"Increíble producto, superó mis expectativas!",
"No funciona como se describe, muy decepcionado",
"Está bien por el precio, pero podría ser mejor"
]
df_analisis = analizar_resenas(resenas_ejemplo)
print("Análisis completo de reseñas:")
print(df_analisis)Paso 12: Recursos y Próximos Pasos
Datasets populares para practicar:
- IMDB Reviews (análisis de sentimientos)
- 20 Newsgroups (clasificación de texto)
- Amazon Product Reviews
- Twitter Sentiment Analysis
Librerías avanzadas:
- spaCy: NLP industrial
- Gensim: Modelado de temas
- Hugging Face Transformers: Modelos state-of-the-art
- Stanza: NLP de Stanford
Próximos temas:
- Traducción automática
- Generación de texto
- Chatbots y sistemas de diálogo
- Análisis de emociones
- NLP multilingüe
Conclusión
¡Felicidades! Ahora dominas los fundamentos del procesamiento de lenguaje natural con Python. Practica con tus propios datasets de texto y explora técnicas más avanzadas. Si tienes preguntas, déjalas en los comentarios.
Para más tutoriales sobre ciencia de datos y Python, visita nuestra sección de tutoriales.
¡Con estos conocimientos ya puedes trabajar con texto y lenguaje natural en Python!
💡 Tip Importante
📝 Mejores Prácticas para NLP
Para desarrollar proyectos efectivos de procesamiento de lenguaje natural, considera estos consejos:
Calidad de datos: Una limpieza exhaustiva del texto es crucial para buenos resultados.
Preprocesamiento adecuado: Adapta el preprocesamiento a tu idioma y dominio específico.
Experimenta con embeddings: Prueba diferentes representaciones vectoriales como Word2Vec, GloVe o FastText.
Considera transformers: Usa modelos como BERT o GPT para tareas complejas de NLP.
Evalúa múltiples métricas: No te limites a la precisión; considera recall, F1-score y otras métricas.
Visualiza resultados: Usa nubes de palabras, clustering de temas y otras visualizaciones para interpretar resultados.
Itera y experimenta: El NLP requiere mucha experimentación para encontrar la mejor aproximación.
📚 Documentación: Revisa la documentación completa de NLTK aquí y spaCy aquí
¡Estos consejos te ayudarán a desarrollar proyectos de NLP efectivos y robustos!



No hay comentarios aún
Sé el primero en comentar este tutorial.