


Análisis Estadístico con Pandas: Guía Completa para Ciencia de Datos
Aprende análisis estadístico con Pandas. Guía paso a paso para principiantes en ciencia de datos con ejemplos prácticos en Python.
¡Da tus primeros pasos en el análisis estadístico con Pandas! En este tutorial completo te guiaré paso a paso para que aprendas a realizar análisis estadísticos avanzados con Pandas, desde estadísticas descriptivas hasta pruebas de hipótesis.
Objetivo: Aprender a usar las funciones estadísticas de Pandas para analizar datos, incluyendo medidas descriptivas, correlaciones, análisis por grupos y pruebas estadísticas.
Paso 1: Configuración Inicial
Instala las bibliotecas necesarias. Abre tu terminal o prompt de comandos y escribe:
pip install pandas numpy scipy matplotlib seaborn scikit-learn statsmodelsUna vez instalado, puedes importarlo en tu código Python:
import pandas as pd
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
# Configuración de visualización
sns.set_style("whitegrid")
plt.rcParams['figure.figsize'] = (10, 6)
# Crear datos de ejemplo para el tutorial
np.random.seed(42)
data = pd.DataFrame({
'edad': np.random.normal(45, 15, 1000),
'ingresos': np.random.lognormal(10, 0.5, 1000),
'genero': np.random.choice(['Hombre', 'Mujer'], 1000, p=[0.6, 0.4]),
'educacion': np.random.choice(['Bachiller', 'Universidad', 'Posgrado'], 1000, p=[0.3, 0.5, 0.2]),
'satisfaccion': np.random.randint(1, 11, 1000),
'horas_trabajo': np.random.normal(40, 8, 1000)
})
# Añadir alguna correlación intencional
data['ingresos'] = data['ingresos'] * (1 + data['educacion'].map({'Bachiller': 0, 'Universidad': 0.2, 'Posgrado': 0.5}))
data['ingresos'] = data['ingresos'] + (data['edad'] * 100)
print("Primeras filas de nuestros datos:")
print(data.head())Paso 2: Estadísticas Descriptivas Básicas
Resúmenes Numéricos
# Estadísticas descriptivas básicas
print("Estadísticas descriptivas:")
print(data.describe())
# Para variables categóricas
print("\nDistribución de categorías:")
print(data['educacion'].value_counts())
# Moda
print(f"\nModa de satisfacción: {data['satisfaccion'].mode()[0]}")
# Percentiles personalizados
print(f"\nPercentiles 10, 50 y 90 de ingresos:")
print(data['ingresos'].quantile([0.1, 0.5, 0.9]))Medidas de Tendencia Central y Dispersión
# Por variable
for col in ['edad', 'ingresos', 'horas_trabajo']:
print(f"\n{col.upper()}:")
print(f"Media: {data[col].mean():.2f}")
print(f"Mediana: {data[col].median():.2f}")
print(f"Desviación estándar: {data[col].std():.2f}")
print(f"Rango intercuartílico (IQR): {data[col].quantile(0.75) - data[col].quantile(0.25):.2f}")Paso 3: Análisis de Correlación
Matriz de Correlación
# Matriz de correlación
corr_matrix = data[['edad', 'ingresos', 'satisfaccion', 'horas_trabajo']].corr()
print("Matriz de correlación:")
print(corr_matrix)
# Visualización con heatmap
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', center=0)
plt.title('Matriz de Correlación')
plt.show()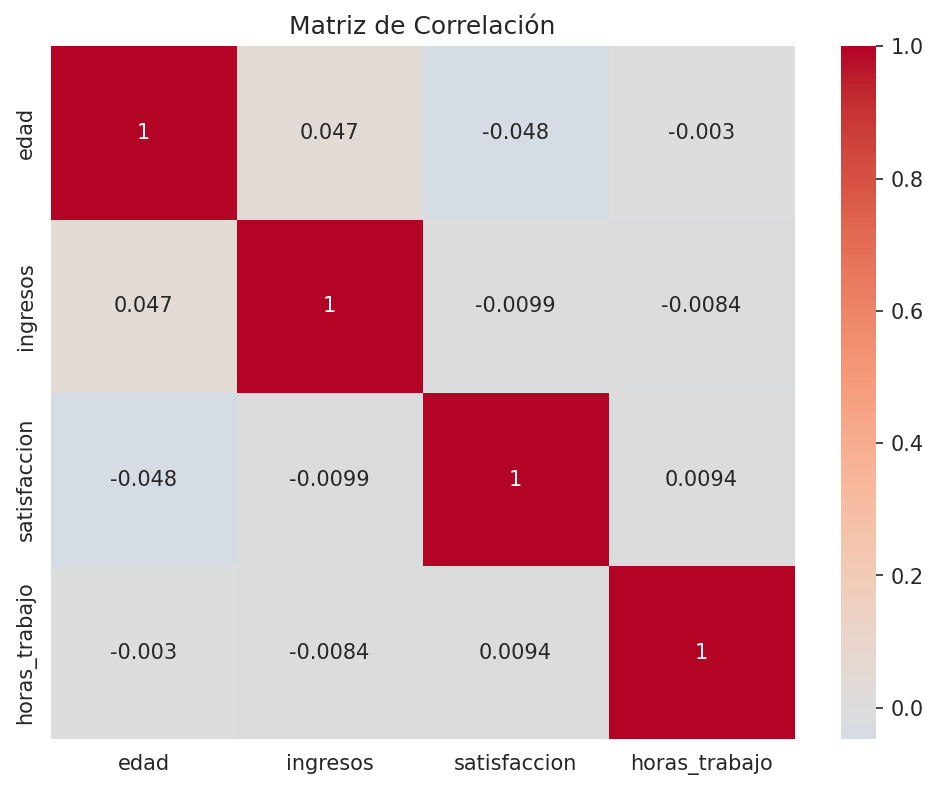
Correlaciones Específicas
# Correlación entre dos variables
corr_edad_ingresos = data['edad'].corr(data['ingresos'])
print(f"Correlación entre edad e ingresos: {corr_edad_ingresos:.3f}")
# Correlación no paramétrica (Spearman)
spearman_corr = data['edad'].corr(data['ingresos'], method='spearman')
print(f"Correlación de Spearman entre edad e ingresos: {spearman_corr:.3f}")
# Correlación por grupos
print("\nCorrelación edad-ingresos por género:")
for genero in data['genero'].unique():
subset = data[data['genero'] == genero]
corr = subset['edad'].corr(subset['ingresos'])
print(f"{genero}: {corr:.3f}")Paso 4: Análisis por Grupos
Comparación de Medias entre Grupos
# Medias por grupo
print("Ingresos medios por educación:")
print(data.groupby('educacion')['ingresos'].mean())
print("\nIngresos medios por género:")
print(data.groupby('genero')['ingresos'].mean())
# Análisis de varianza (ANOVA)
grupos = [data[data['educacion'] == nivel]['ingresos'] for nivel in data['educacion'].unique()]
f_val, p_val = stats.f_oneway(*grupos)
print(f"\nANOVA para ingresos por educación: F={f_val:.3f}, p={p_val:.4f}")
# Test t para dos grupos
hombres = data[data['genero'] == 'Hombre']['ingresos']
mujeres = data[data['genero'] == 'Mujer']['ingresos']
t_val, p_val = stats.ttest_ind(hombres, mujeres)
print(f"Test t para ingresos por género: t={t_val:.3f}, p={p_val:.4f}")Análisis de Varianza con Agrupación Múltiple
# Tabla pivote para análisis multivariado
pivot_ingresos = pd.pivot_table(data,
values='ingresos',
index='genero',
columns='educacion',
aggfunc='mean')
print("Ingresos medios por género y educación:")
print(pivot_ingresos)
# Visualización de interacciones
data.groupby(['educacion', 'genero'])['ingresos'].mean().unstack().plot(kind='bar')
plt.title('Ingresos medios por Educación y Género')
plt.ylabel('Ingresos')
plt.xticks(rotation=45)
plt.legend(title='Género')
plt.show()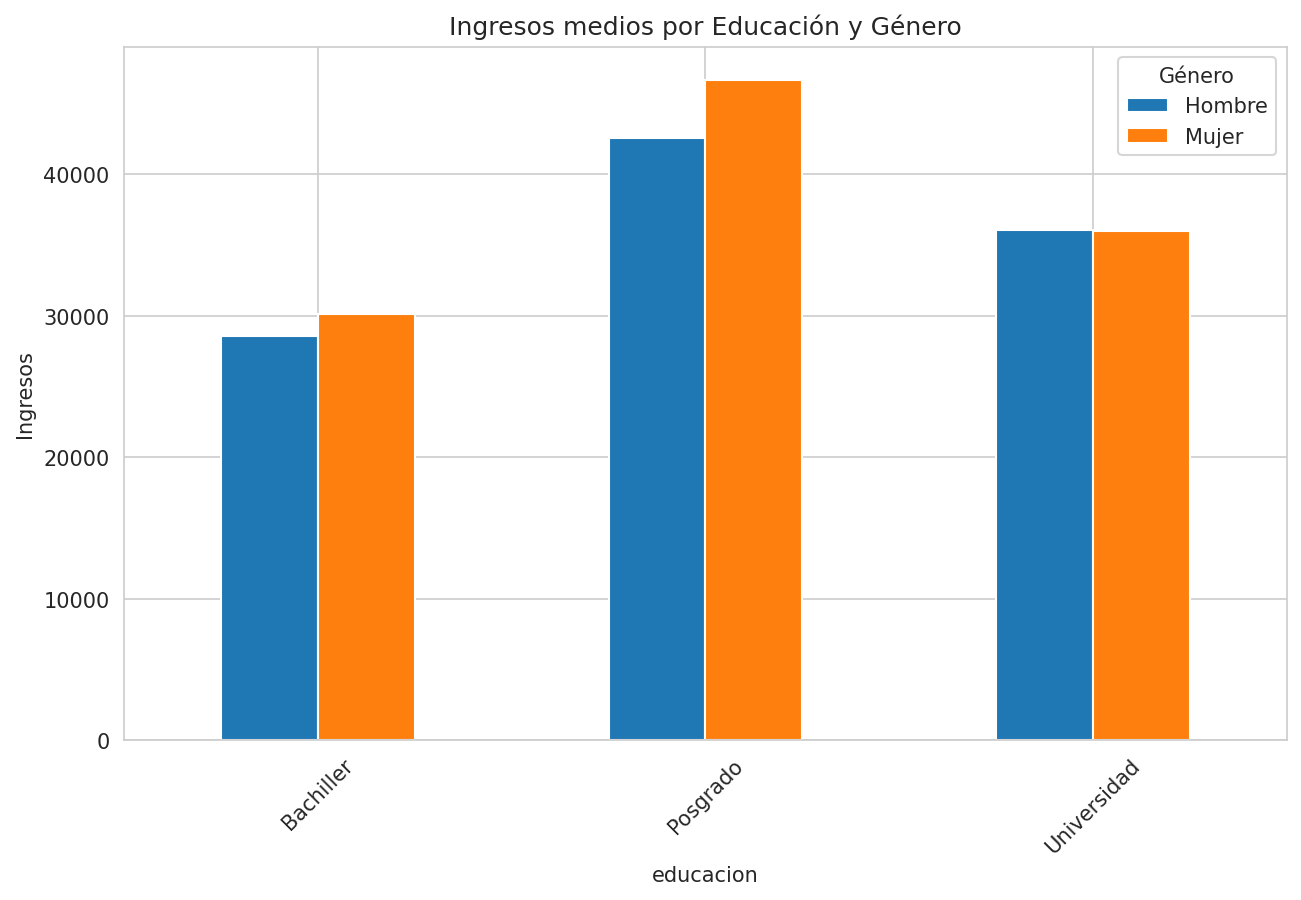
Paso 5: Análisis de Distribuciones
Pruebas de Normalidad
# Test de normalidad (Shapiro-Wilk)
stat, p = stats.shapiro(data['ingresos'])
print(f"Test de normalidad para ingresos: estadístico={stat:.3f}, p={p:.4f}")
# Histograma con curva normal
plt.figure(figsize=(10, 6))
sns.histplot(data['ingresos'], kde=True, stat='density')
plt.title('Distribución de Ingresos')
plt.show()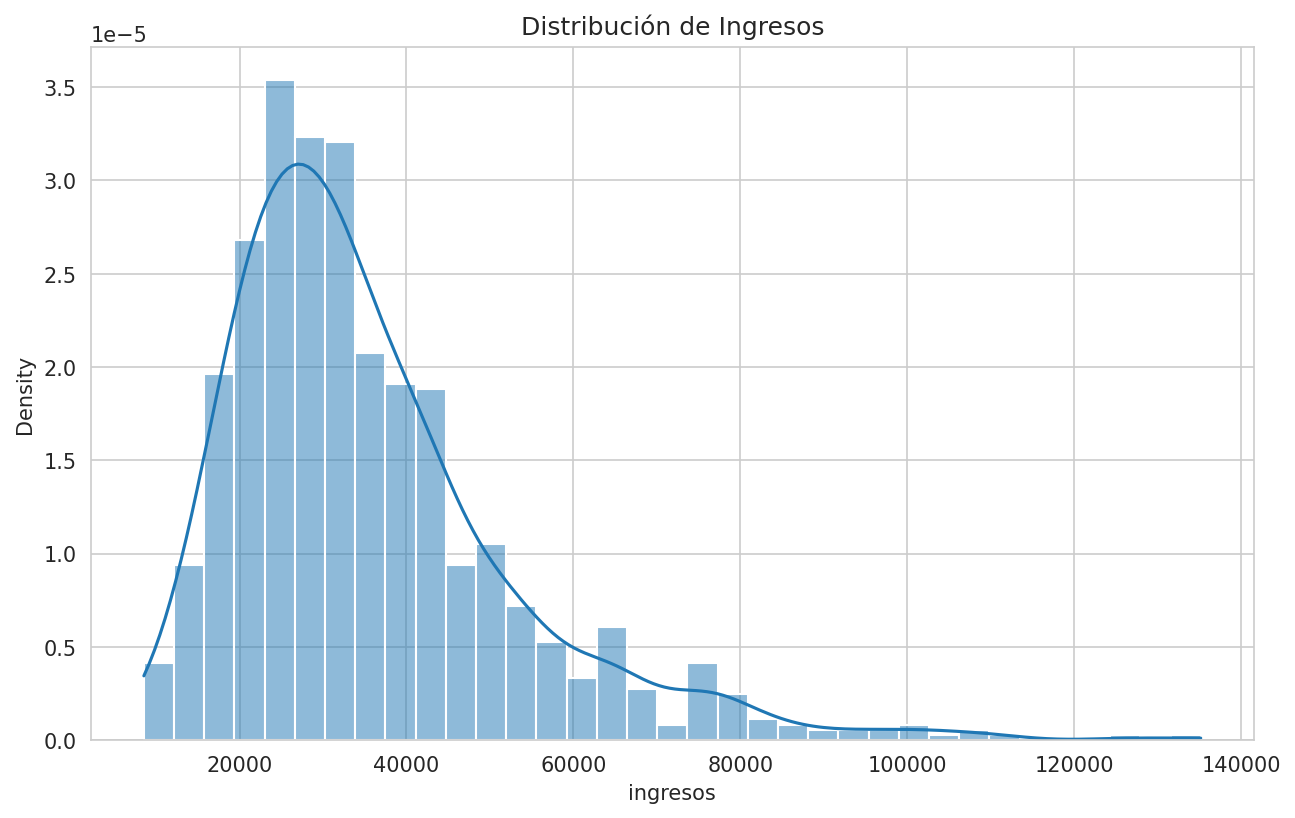
# Q-Q plot
plt.figure(figsize=(8, 6))
stats.probplot(data['ingresos'], dist="norm", plot=plt)
plt.title('Q-Q Plot de Ingresos')
plt.show()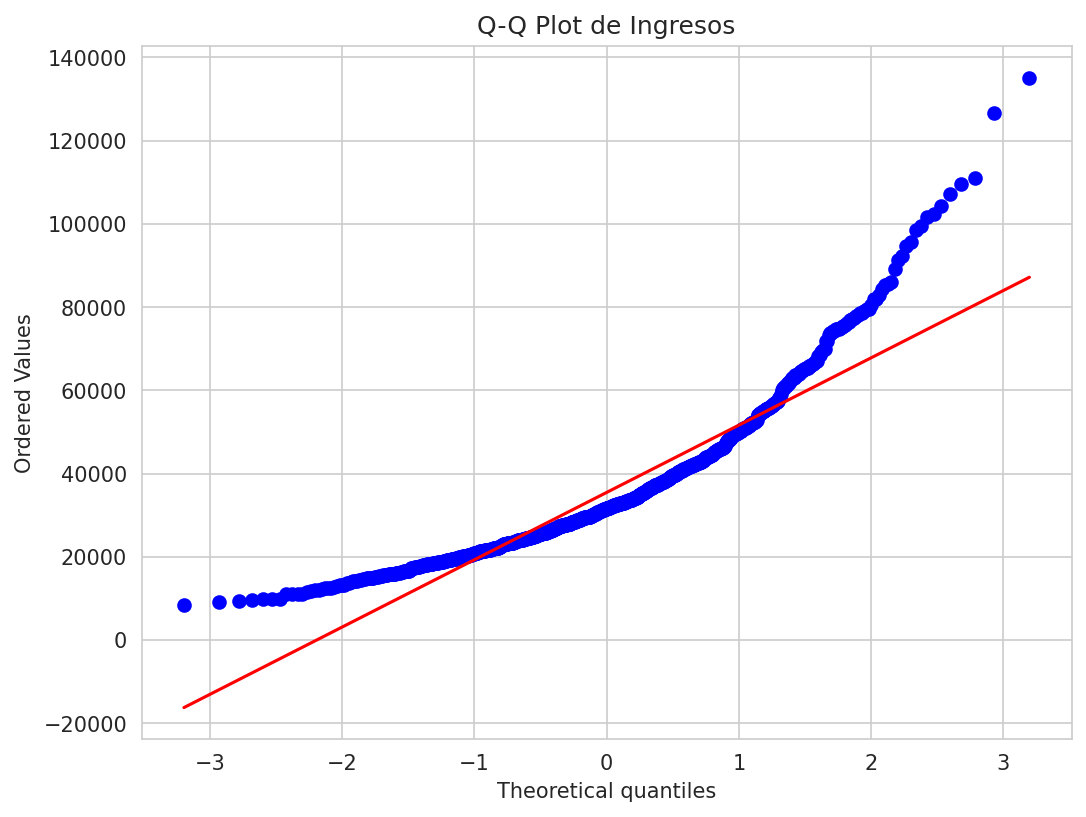
Comparación de Distribuciones
# Comparar distribuciones entre grupos
plt.figure(figsize=(12, 6))
# Boxplot
plt.subplot(1, 2, 1)
sns.boxplot(x='educacion', y='ingresos', data=data)
plt.title('Distribución de Ingresos por Educación')
plt.xticks(rotation=45)
# Violin plot
plt.subplot(1, 2, 2)
sns.violinplot(x='educacion', y='ingresos', data=data)
plt.title('Distribución de Densidad de Ingresos por Educación')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()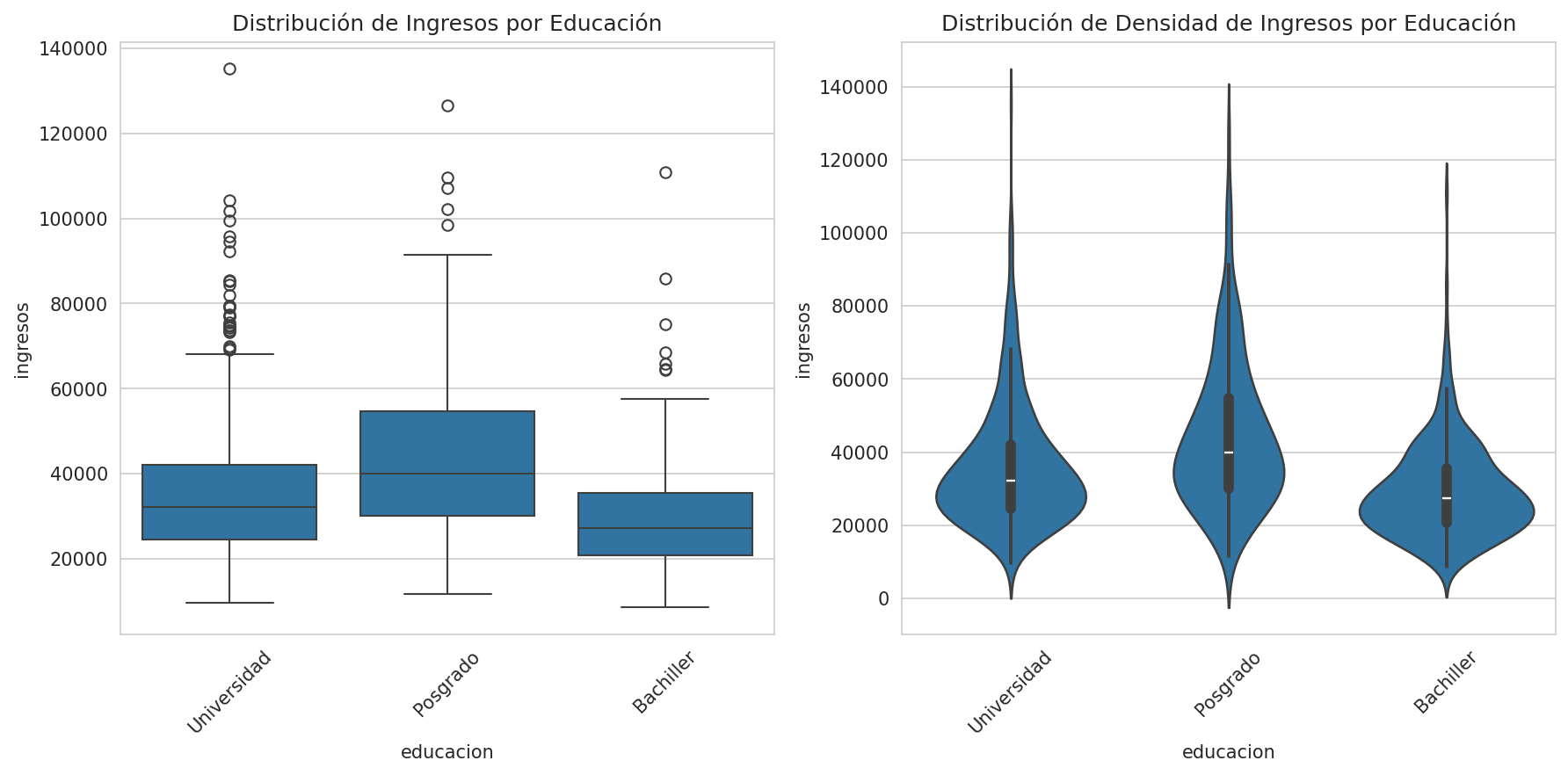
# Test de Kolmogorov-Smirnov para comparar distribuciones
bachiller = data[data['educacion'] == 'Bachiller']['ingresos']
posgrado = data[data['educacion'] == 'Posgrado']['ingresos']
ks_stat, ks_p = stats.ks_2samp(bachiller, posgrado)
print(f"Test KS entre Bachiller y Posgrado: estadístico={ks_stat:.3f}, p={ks_p:.4f}")Paso 6: Análisis de Regresión
Regresión Lineal Simple
# Ajustar un modelo de regresión lineal
from sklearn.linear_model import LinearRegression
# Preparar datos
X = data[['edad']]
y = data['ingresos']
# Ajustar modelo
modelo = LinearRegression()
modelo.fit(X, y)
# Resultados
print(f"Intercepto: {modelo.intercept_:.2f}")
print(f"Coeficiente de edad: {modelo.coef_[0]:.2f}")
print(f"R-cuadrado: {modelo.score(X, y):.3f}")
# Visualizar regresión
plt.figure(figsize=(10, 6))
plt.scatter(data['edad'], data['ingresos'], alpha=0.5)
plt.plot(data['edad'], modelo.predict(X), color='red', linewidth=2)
plt.title('Regresión Lineal: Ingresos vs Edad')
plt.xlabel('Edad')
plt.ylabel('Ingresos')
plt.show()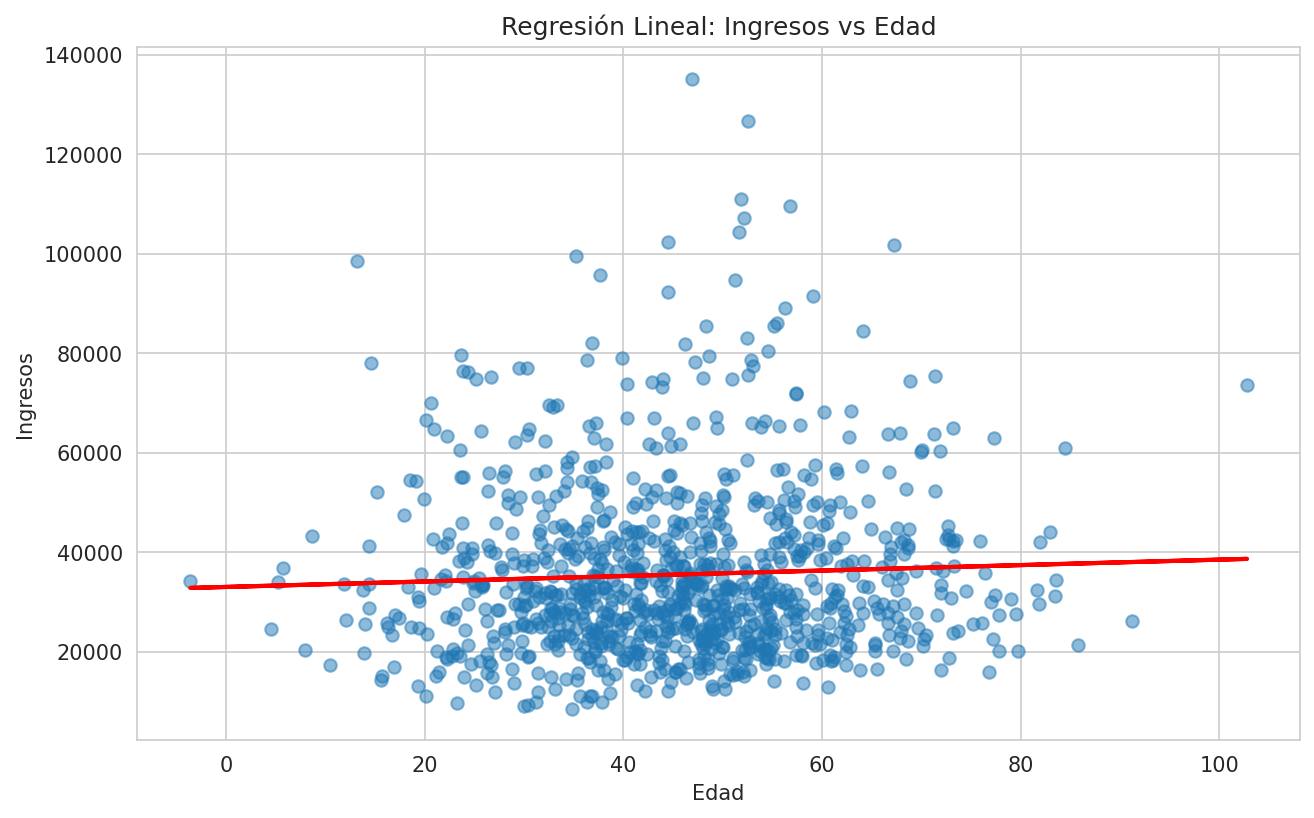
Regresión Múltiple
# Preparar datos para regresión múltiple
X_multi = data[['edad', 'horas_trabajo']]
y_multi = data['ingresos']
# Ajustar modelo
modelo_multi = LinearRegression()
modelo_multi.fit(X_multi, y_multi)
# Resultados
print("Regresión múltiple: Ingresos ~ Edad + Horas_trabajo")
print(f"Intercepto: {modelo_multi.intercept_:.2f}")
print(f"Coeficientes: {modelo_multi.coef_}")
print(f"R-cuadrado: {modelo_multi.score(X_multi, y_multi):.3f}")
# Crear DataFrame con coeficientes
coeficientes = pd.DataFrame({
'Variable': ['Edad', 'Horas_trabajo'],
'Coeficiente': modelo_multi.coef_,
'Absoluto': np.abs(modelo_multi.coef_)
}).sort_values('Absoluto', ascending=False)
print("\nImportancia de variables (por coeficiente absoluto):")
print(coeficientes)Paso 7: Análisis de Series Temporales
# Crear datos de serie temporal
fechas = pd.date_range('2020-01-01', '2022-12-31', freq='D')
serie_temporal = pd.DataFrame({
'fecha': fechas,
'valor': np.sin(2 * np.pi * np.arange(len(fechas)) / 365) + np.random.normal(0, 0.2, len(fechas))
})
# Establecer fecha como índice
serie_temporal.set_index('fecha', inplace=True)
# Estadísticas de serie temporal
print("Estadísticas de serie temporal:")
print(f"Media: {serie_temporal['valor'].mean():.3f}")
print(f"Desviación estándar: {serie_temporal['valor'].std():.3f}")
print(f"Autocorrelación (lag=1): {serie_temporal['valor'].autocorr(lag=1):.3f}")
# Descomposición de tendencia y estacionalidad
from statsmodels.tsa.seasonal import seasonal_decompose
resultado = seasonal_decompose(serie_temporal['valor'].iloc[:730], # Primeros 2 años
model='additive',
period=365)
resultado.plot()
plt.suptitle('Descomposición de Serie Temporal')
plt.show()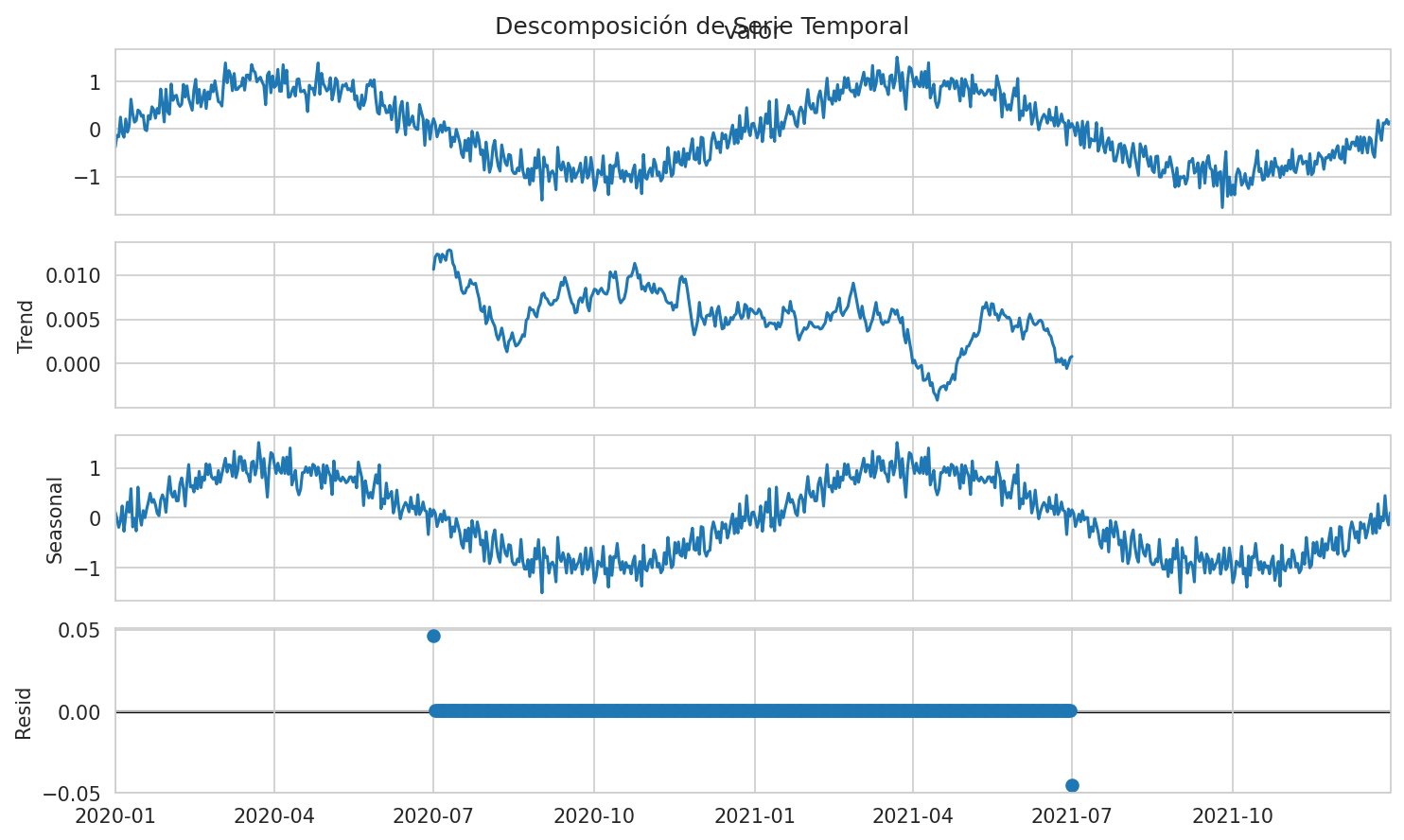
Paso 8: Análisis de Asociación para Variables Categóricas
# Tabla de contingencia
tabla_contingencia = pd.crosstab(data['genero'], data['educacion'])
print("Tabla de contingencia: Género vs Educación")
print(tabla_contingencia)
# Test chi-cuadrado
chi2, p, dof, expected = stats.chi2_contingency(tabla_contingencia)
print(f"\nTest Chi-cuadrado: χ²={chi2:.3f}, p={p:.4f}, gl={dof}")
# Visualización de asociación
plt.figure(figsize=(8, 6))
sns.heatmap(tabla_contingencia, annot=True, fmt='d', cmap='Blues')
plt.title('Asociación entre Género y Educación')
plt.show()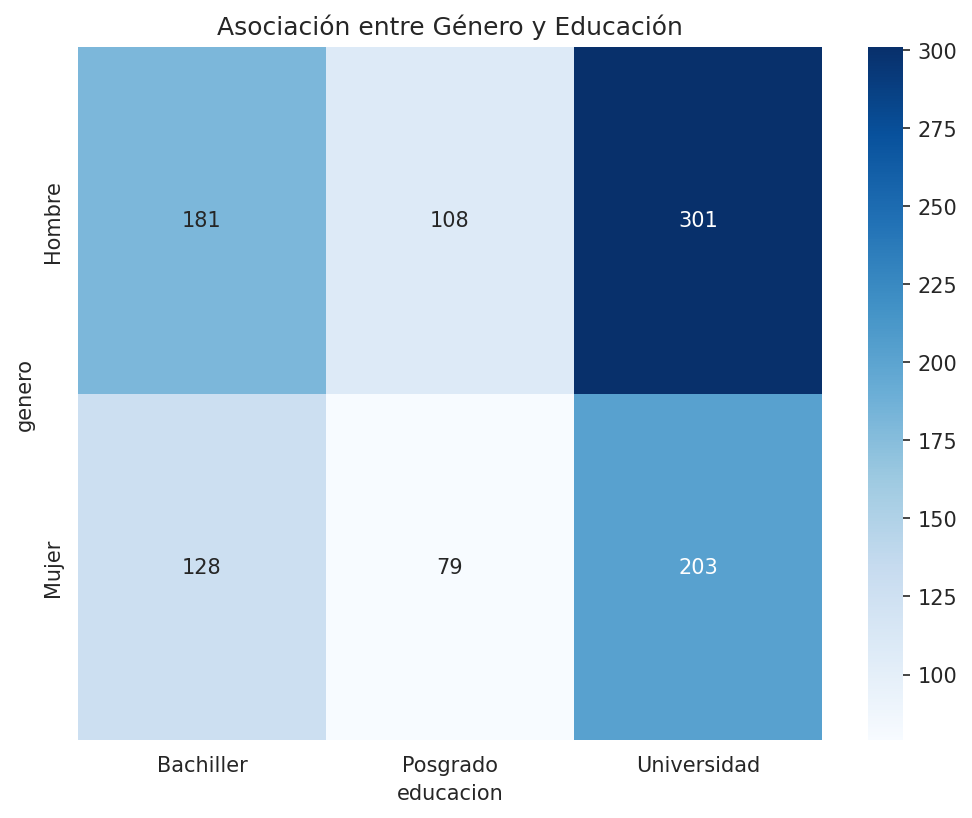
Paso 9: Análisis de Outliers con Métodos Estadísticos
# Identificar outliers con el método IQR
def identificar_outliers_iqr(serie):
Q1 = serie.quantile(0.25)
Q3 = serie.quantile(0.75)
IQR = Q3 - Q1
limite_inferior = Q1 - 1.5 * IQR
limite_superior = Q3 + 1.5 * IQR
outliers = serie[(serie < limite_inferior) | (serie > limite_superior)]
return outliers
outliers_ingresos = identificar_outliers_iqr(data['ingresos'])
print(f"Número de outliers en ingresos: {len(outliers_ingresos)}")
print(f"Porcentaje de outliers: {len(outliers_ingresos)/len(data)*100:.2f}%")
# Identificar outliers con puntuación Z
def identificar_outliers_zscore(serie, umbral=3):
z_scores = np.abs(stats.zscore(serie))
outliers = serie[z_scores > umbral]
return outliers
outliers_z = identificar_outliers_zscore(data['ingresos'])
print(f"Número de outliers (Z-score > 3): {len(outliers_z)}")Paso 10: Guardar Resultados del Análisis
# Crear un resumen estadístico
resumen_estadistico = data.describe().round(2)
# Añadir algunas medidas adicionales
resumen_estadistico.loc['skew'] = data.skew(numeric_only=True)
resumen_estadistico.loc['kurtosis'] = data.kurtosis(numeric_only=True)
print("Resumen estadístico completo:")
print(resumen_estadistico)
# Guardar resultados en Excel
with pd.ExcelWriter('analisis_estadistico.xlsx') as writer:
data.describe().to_excel(writer, sheet_name='Estadisticas_descriptivas')
data.corr().to_excel(writer, sheet_name='Correlaciones')
pd.crosstab(data['genero'], data['educacion']).to_excel(writer, sheet_name='Tabla_contingencia')Conclusión
¡Felicidades! Ahora dominas los fundamentos del análisis estadístico con Pandas. Practica con tus propios datasets y explora más técnicas avanzadas. Si tienes preguntas, déjalas en los comentarios.
Para más tutoriales sobre ciencia de datos y Python, visita nuestra sección de tutoriales.
¡Con estos conocimientos ya puedes realizar análisis estadísticos completos en Python usando Pandas!
💡 Tip Importante
📊 Mejores Prácticas para Análisis Estadístico
Para realizar análisis estadísticos efectivos y confiables, considera estos consejos:
Comprende tus datos antes de aplicar cualquier test estadístico.
Verifica supuestos de normalidad, homocedasticidad, etc.
Considera transformaciones (log, raíz cuadrada) si es necesario.
Interpreta en contexto - la significancia estadística no siempre implica importancia práctica.
Documenta tu proceso para asegurar la reproducibilidad.
Usa visualizaciones para comunicar tus hallazgos de manera efectiva.
Combina métodos para obtener una comprensión más completa.
📚 Documentación: Revisa la documentación completa de pandas para análisis estadístico aquí
¡Estos consejos te ayudarán a realizar análisis estadísticos robustos y significativos!





No hay comentarios aún
Sé el primero en comentar este tutorial.