

Embeddings y su Impacto en el Procesamiento de Texto
1 AGO., 2026
//1 min. de Lectura
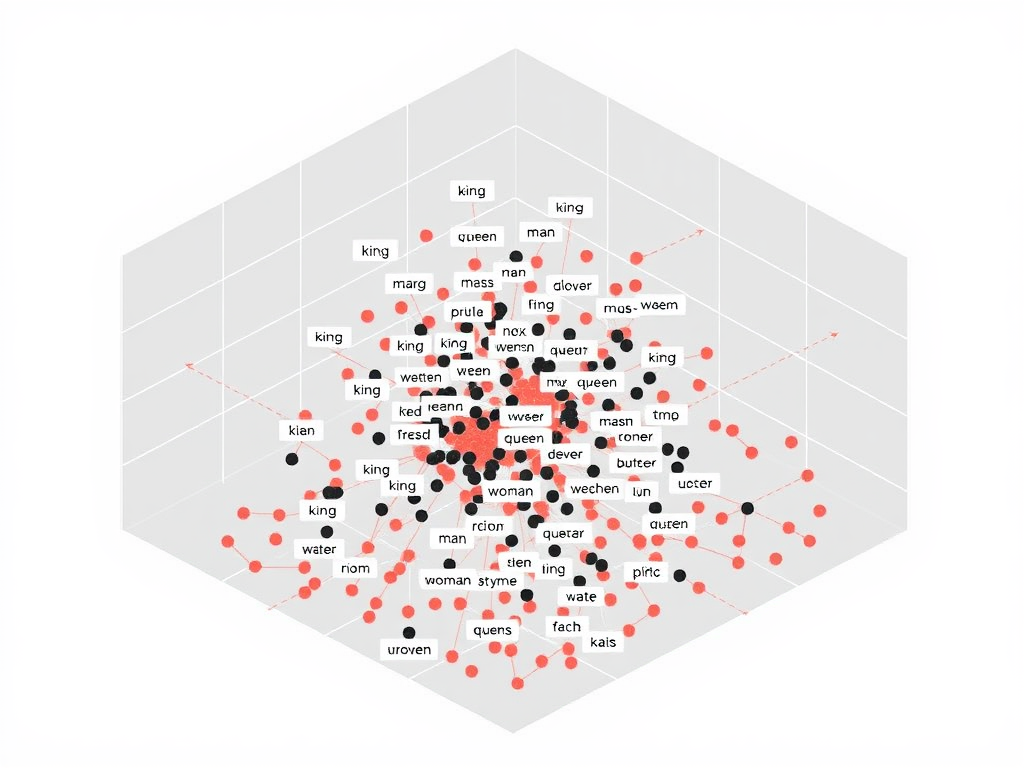
En el mundo del procesamiento de lenguaje natural (NLP), los embeddings han revolucionado la forma en que los modelos comprenden y manipulan el lenguaje. Estas representaciones densas y continuas de palabras y frases han permitido avances significativos en una variedad de aplicaciones, desde la traducción automática hasta el análisis de sentimientos. En este artículo, nosotros exploraremos qué son los embeddings, cómo funcionan, su impacto en el procesamiento de texto y responderemos algunas preguntas frecuentes que pueden surgir sobre este tema.
¿Qué Son los Embeddings?
Los embeddings son representaciones vectoriales de palabras o frases en un espacio de alta dimensión. A diferencia de las representaciones tradicionales, como el one-hot encoding, que asigna un vector escaso a cada palabra, los embeddings permiten que palabras con significados similares estén más cerca entre sí en el espacio vectorial. Esto se logra a través de técnicas de aprendizaje automático que capturan el contexto y la semántica de las palabras en función de su uso en grandes corpus de texto.
¿Cómo Funcionan los Embeddings?
El proceso para generar embeddings implica varias etapas clave. A continuación, nosotros desglosaremos este proceso:
1. Recolección de Datos Textuales
El primer paso es recolectar un gran corpus de texto que represente el lenguaje que se desea modelar. Este corpus puede provenir de diversas fuentes, como libros, artículos, redes sociales o cualquier otro lugar donde se utilice el lenguaje natural. Cuanto más diverso y amplio sea el corpus, mejor será la calidad de los embeddings generados.
2. Preprocesamiento del Texto
Una vez que se ha recolectado el texto, se pasa por un proceso de preprocesamiento. Este paso incluye la limpieza del texto, la tokenización (división del texto en palabras o frases), la eliminación de stop words (palabras comunes que no aportan valor semántico) y la normalización (como la conversión a minúsculas). Este proceso asegura que los datos estén listos para ser utilizados en el entrenamiento de modelos.
3. Entrenamiento del Modelo
Los embeddings se generan mediante técnicas de aprendizaje automático, como Word2Vec, GloVe o FastText. Estos modelos analizan el contexto en el que aparecen las palabras en el corpus y ajustan los pesos en sus representaciones vectoriales para que palabras que aparecen en contextos similares tengan vectores más cercanos. Este proceso se basa en la idea de que "las palabras que aparecen en el mismo contexto tienden a tener significados similares".
Impacto de los Embeddings en el Procesamiento de Texto
Los embeddings han tenido un impacto significativo en varias áreas del procesamiento de lenguaje natural. A continuación, nosotros exploraremos algunas de las aplicaciones más destacadas:
1. Mejora en la Clasificación de Texto
Los embeddings permiten que los modelos de clasificación de texto trabajen con representaciones más ricas y significativas de las palabras. Esto se traduce en una mejor precisión en tareas como la detección de spam, la categorización de documentos y el análisis de sentimientos. Al capturar la relación semántica entre las palabras, los modelos pueden realizar predicciones más informadas.
2. Traducción Automática
En la traducción automática, los embeddings juegan un papel crucial al facilitar la comprensión del contexto y el significado de las palabras en diferentes idiomas. Modelos como los utilizados en Google Translate han mejorado enormemente gracias a la implementación de embeddings, lo que ha permitido traducciones más precisas y fluidas.
3. Generación de Texto
Los embeddings también son esenciales en la generación de texto. Modelos como GPT-3 utilizan embeddings para generar texto coherente y relevante en respuesta a un input. Al entender las relaciones semánticas entre las palabras, estos modelos son capaces de crear contenido que no solo es gramaticalmente correcto, sino también contextualmente apropiado.
Desafíos y Limitaciones de los Embeddings
Aunque los embeddings han demostrado ser una herramienta poderosa en el procesamiento de lenguaje natural, también presentan ciertos desafíos y limitaciones. Algunos de estos incluyen:
1. Sesgos en los Datos
Los embeddings pueden reflejar sesgos presentes en el corpus de entrenamiento. Por ejemplo, si un modelo es entrenado con datos que contienen estereotipos, estos se pueden perpetuar en las representaciones vectoriales. Esto puede llevar a resultados sesgados en aplicaciones prácticas, como la selección de personal o el análisis social.
2. Dimensionalidad Alta
La representación de palabras en un espacio de alta dimensión puede hacer que los modelos sean más complejos y requieran más recursos computacionales. Esto puede resultar en tiempos de entrenamiento prolongados y una mayor necesidad de memoria, lo que puede ser un desafío en entornos con recursos limitados.
3. Interpretabilidad
Entender cómo un modelo ha llegado a ciertas conclusiones es un desafío en el campo del aprendizaje automático. Los embeddings, al ser representaciones densas, pueden ser difíciles de interpretar. Esto plantea preguntas sobre la transparencia y la confianza en los modelos que utilizan estos embeddings para tomar decisiones.
Preguntas Frecuentes (FAQs)
¿Qué son los embeddings en el procesamiento de lenguaje natural?
Los embeddings son representaciones vectoriales de palabras o frases que permiten capturar el contexto y la semántica en el procesamiento de lenguaje natural. Facilitan que los modelos comprendan relaciones entre palabras en un espacio de alta dimensión.
¿Cuáles son las técnicas más comunes para generar embeddings?
Las técnicas más comunes incluyen Word2Vec, GloVe y FastText. Estas técnicas utilizan diferentes enfoques para capturar el contexto de las palabras y generar sus representaciones vectoriales.
¿Qué problemas pueden surgir al usar embeddings?
Algunos problemas incluyen sesgos en los datos de entrenamiento, alta dimensionalidad que puede complicar el entrenamiento de modelos, y la dificultad de interpretar cómo se toman decisiones basadas en embeddings.
Los embeddings han transformado el campo del procesamiento de lenguaje natural, permitiendo a los modelos entender y manipular el lenguaje de manera más efectiva. A pesar de los desafíos que presentan, su impacto en aplicaciones como la traducción automática, la clasificación de texto y la generación de contenido es innegable. A medida que continuamos avanzando en el desarrollo de nuevas técnicas y enfoques, los embeddings seguirán siendo una herramienta esencial en nuestro esfuerzo por mejorar la interacción entre humanos y máquinas. Con cada avance, nosotros nos acercamos más a una comprensión más profunda y eficiente del lenguaje natural.
Comentarios
0Sin comentarios
Sé el primero en compartir tu opinión.
También te puede interesar
Descubre más contenido relacionado que podría ser de tu interés

Gradient Boosted Trees desde Cero: Matemáticas y Código Python
desglosaremos capa por capa la maquinaria de los GBT, desde los fundamentos matemáticos hasta una implementación en Python desde cero

Secretos de Feature Engineering: Domina Creación de Variables en Python
El feature engineering es ese arte transformador que convierte variables simples en poderosos predictores
